

Avec la digitalisation croissante des activités, les entreprises font face à une augmentation exponentielle des données, générées en interne ou bien par leurs clients. Les données sont stockées dans des bases différentes et existent sous de multiples formes.
Pour tirer pleinement profit de ces sources d’information et dégager de la valeur, il faut pouvoir combiner et analyser les différentes sources de données de l’entreprise, voire même de les croiser en temps réel avec des données disponibles en Open Data. Pour ce faire, plusieurs méthodes existent dont la Data Virtualisation.
Cette méthode s’avère extrêmement efficace car elle permet de réduire les coûts de stockage, les délais d’intégration tout en garantissant un accès unifié et en temps réel aux sources de données sans les répliquer ou les déplacer. Comment ? Lisez notre article ci-dessous.
Data Lake, Entreprise Data Warehouse ou Data Virtualisation ?
Avec la digitalisation croissante des activités, les entreprises font de plus en plus souvent face à une augmentation exponentielle des données, générées en interne ou par leurs clients. Les données sont stockées dans des bases différentes et ont de multiples formes : données structurées issues des systèmes transactionnels ou données non structurées comme des mails, des images, des vidéos, des pdf, des données issues d’IoT, des données de géolocalisation, des données de maintenance, des données de processus de fabrication, des logs systèmes, etc.
Pour tirer pleinement profit de ces sources d’information et dégager de la valeur, il faut pouvoir combiner et analyser les différentes sources de données de l’entreprise voire même de les croiser en temps réel avec des données disponibles en Open Data.
Pour atteindre cet objectif les entreprises sont confrontées à des défis organisationnels et techniques. La sécurisation et la gouvernance des données sont devenues primordiales pour pouvoir mettre à disposition des métiers de l’entreprise un catalogue des données et un accès en self-service. Pour relever ces défis les architectes de données préconisent souvent de rassembler, recopier l’ensemble des sources de données dans un système unique pour assurer la sécurisation et la gouvernance des données tels qu’un « Entreprise Data Warehouse » (EDW) ou un « Data Lake ».
Les données stockées dans un EDW sont transformées et structurées de manière à les rendre directement interrogeables par des outils de BI, tandis que dans un Data Lake les données sont brutes et non structurées. Contrairement aux Data Warehouse, les Data Lakes sont davantage utilisées par les Data Engineers et Data Scientistes pour travailler sur des Datasets de données brutes de grandes tailles. Les coûts de stockage dans un Data Warehouse sont cependant beaucoup plus élevés que dans un Data Lake comme Hadoop ou AWS S3 conçus pour du stockage low-cost. Le Data Lake et le Data Warehouse sont optimisés pour des usages différents et ils doivent être utilisés pour ce pour quoi ils ont été conçus. Ces deux approches du stockage de masse peuvent cependant être unifiées grâce à la Data Virtualisation.
Duplication ou virtualisation ?
La connexion des sources de données (CRM, ERP, IoT, cloud ) à l’EDW ou au Data Lake nécessite la mise en place et la maintenance de workflow pour leurs chargements. Cette activité engendre des duplications de données, des délais et des coûts à chaque ajout de nouvelles sources. Cela peut nuire fortement à l’agilité de l’organisation pour la proposition et l’intégration de nouveaux services basés sur les données. En utilisant des connecteurs directs aux sources, la Data Virtualisation permet de réduire les coûts de stockage, les coûts et les délais d’intégration. Elle permet ainsi de réaliser simplement et à moindres coûts la fédération et la mise en relation de sources dispersées et disparates de données des différentes sources de l’entreprise, qu’elles soient sur site ou dans le Cloud.
Qu’est-ce que la Data Virtualisation ?
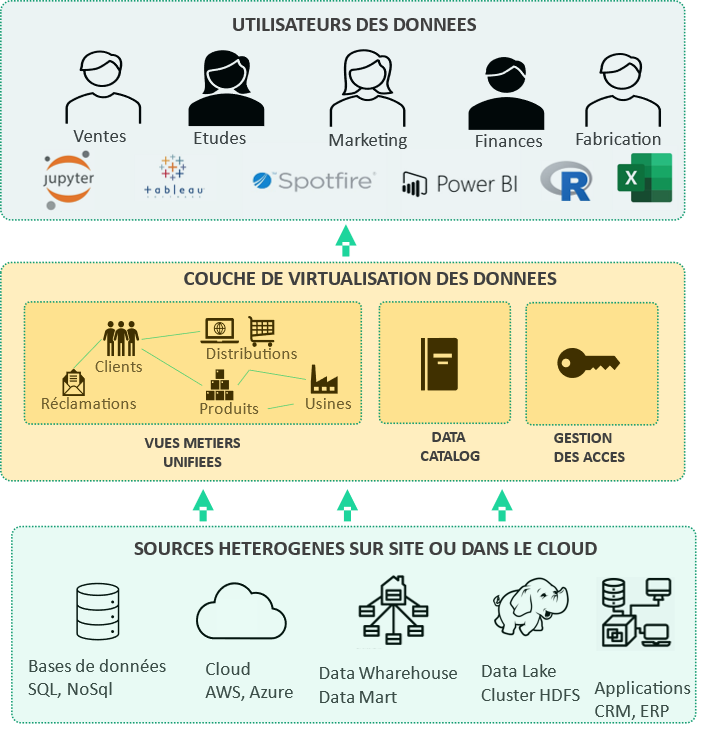
La Data Virtualisation est une technologie agile d’intégration de données qui permet un accès unifié et en temps réel aux sources de données sans les répliquer ou les déplacer. On peut ainsi créer une vision fédérant les données disponibles au travers de vues métiers utilisant des sources très différentes et dispersées. Pour garantir les performances, des mécanismes de cache et d’optimisation des jointures sont mis en œuvre.
La couche de Data Virtualisation fournit un accès générique via des protocoles standards (JDBC, ODBC, REST, SOAP…). La complexité de l’accès aux données et l’optimisation des requêtes sont ainsi masquées. L’utilisateur interagit uniquement avec le moteur de Data Virtualisation via le langage SQL alors que les sources peuvent utiliser d’autres dialectes d’interrogation plus complexes. La Data Virtualisation apporte aussi une couche de gestion fine de la sécurité́ et de l’accès à ces vues. Elle fournit également un « Data Catalog» pour permettre aux métiers de trouver rapidement et en libre-service les Datasets dont ils ont besoin.
Cas d’usage de la data virtualisation pour une data plateforme métier agile
Si vous n’avez que quelques sources de données à fédérer, vous n’avez probablement pas besoin d’une solution de Data Virtualisation. En revanche, la Data Virtualisation sera pertinente pour unifier de nombreuses sources de données telles que CRM, ERP, bases de données applicatives, Data Lake et/ou Data Warehouse sur site ou dans le cloud.
Quel est le délai de mise en œuvre d’une Data Plateforme métier en utilisant la Data Virtualisation ?
En quelques semaines, il est possible de fédérer un ensemble de bases de données disparates en fournissant un « Data Catalog » avec des jeux de données en self-service sous différents format (JDBC, ODBC, REST, SOAP). Les vues métiers sont directement accessibles aux outils traditionnels de BI ou aux Data Scientistes. La mise en œuvre peut être rapide. En effet, la Data Virtualisation utilise les infrastructures de stockage et de calcul déjà en place. Il n’y a plus de workflow de transfert de données à configurer qui peuvent être longs et complexes. Il suffit de paramétrer les connecteurs pour accéder aux sources de données. Lors de la mise en place de la solution, le Data Engineer se consacre alors essentiellement à la sémantique des données et à la définition des vues métiers plutôt qu’à la synchronisation et à la réplication de données sans valeur ajoutée pour l’entreprise.
Sources :
